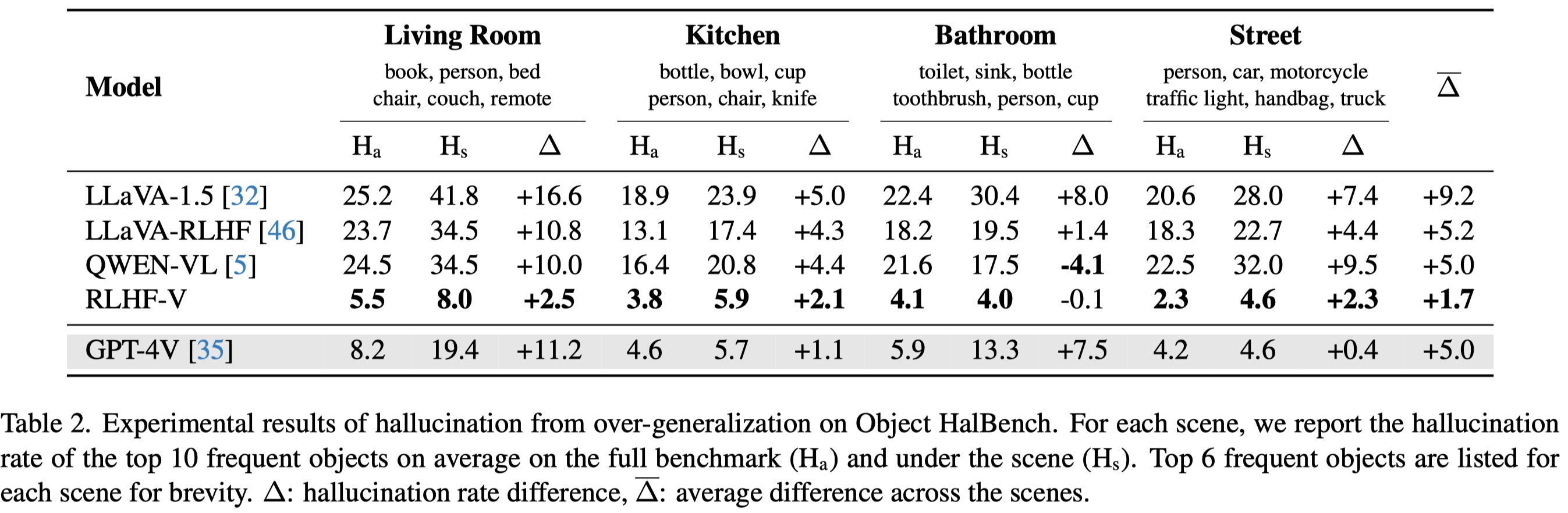
Method
The proposed RLHF-V framework:
We collect 1.4k fine-grained dense feedback data by asking human annotators to correct the hallucinated segments in model responses. The training takes only 1 hour with 8 A100 GPUs to get RLHF-V-13B which is initialized from our RLHF-V_SFT-13B.
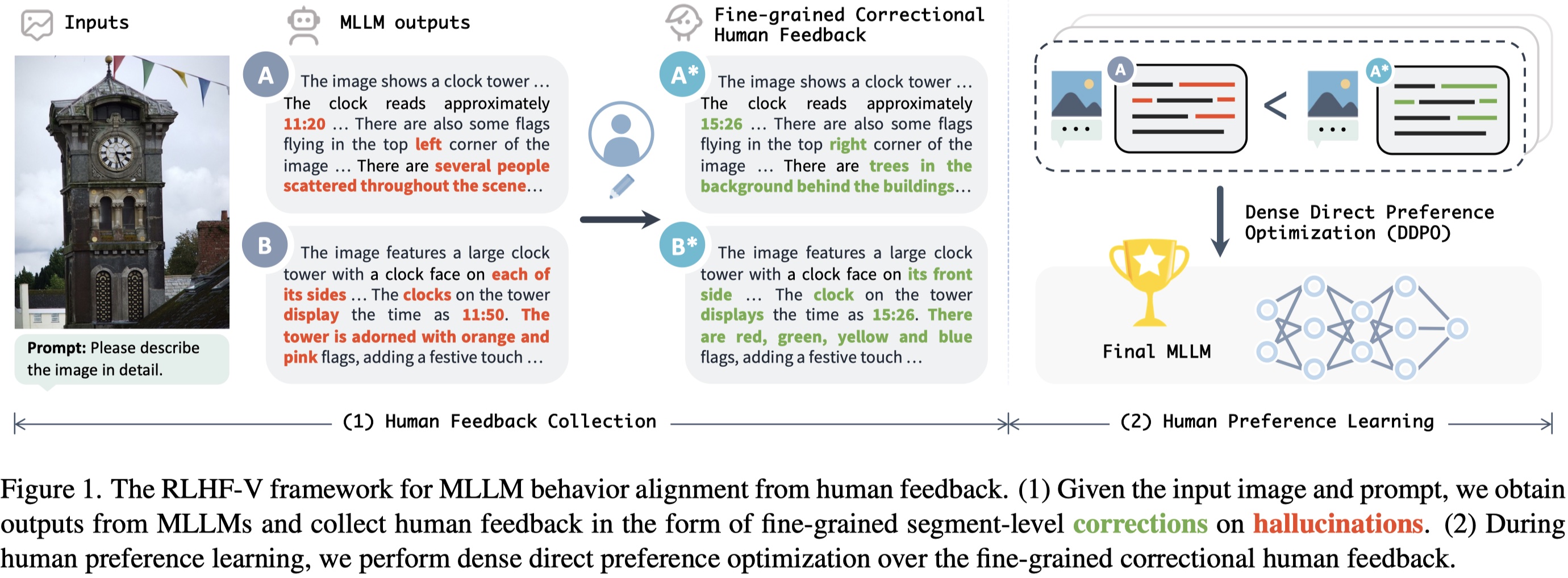
Highlights
Low hallucination rate while being informative:
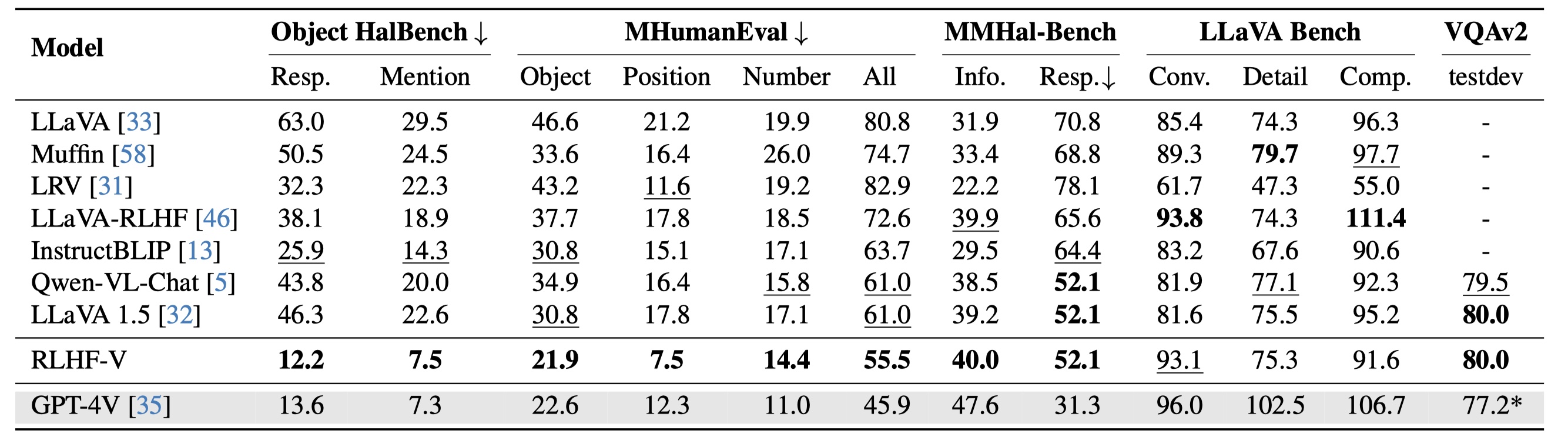
Data-efficient and showing good scaling results:
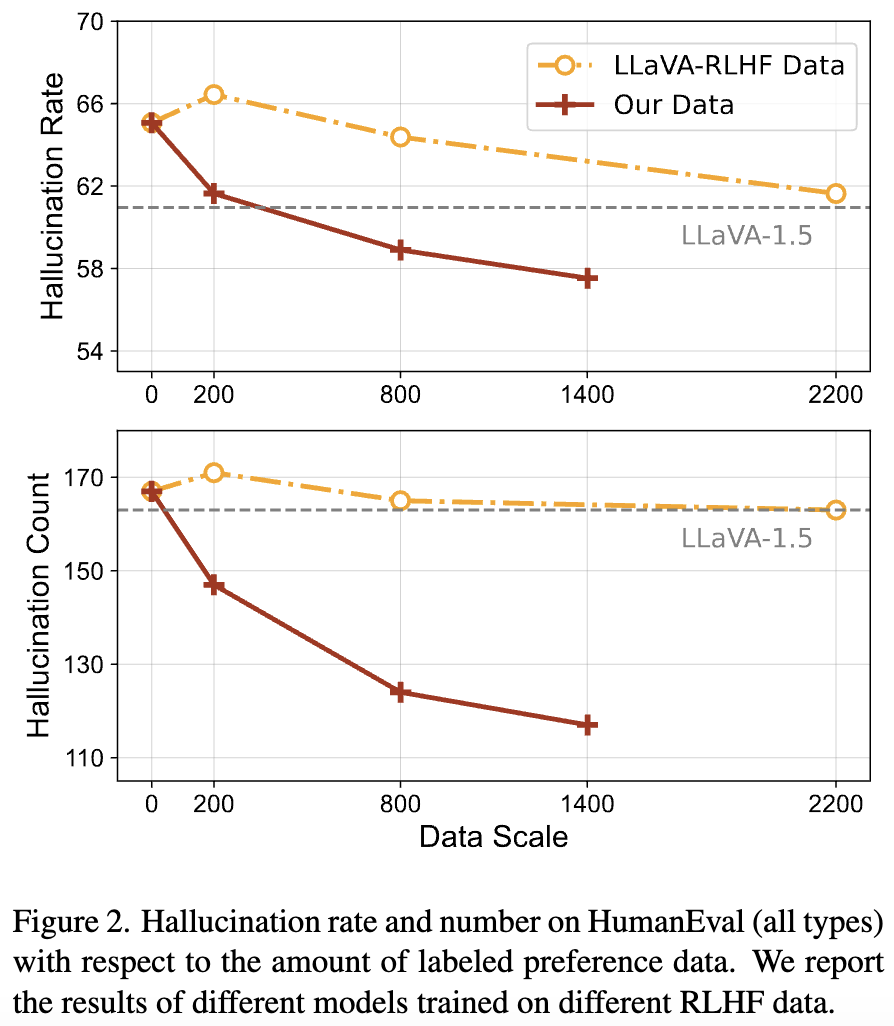
More resistant to over-generalization: